
Debug 过程总结
问题背景 (主要问题)
- 问题描述
- 在基于 Shardingsphere 5.2.0 版本实现订单表与订单明细表分库分表时 bindtables 参数因 yml 配置格式不熟悉导致绑定表的配置无法生效, 查询出现笛卡尔积现象.
- Shardingsphere 相关依赖
1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-namespace</artifactId>
<version>5.2.0</version>
</dependency> - 配置
- 修正前
- 配置
1
2
3
4
5
6
7
8spring:
shardingsphere:
# 数据源配置
datasource:
...
rules:
...
binding-tables: t_order,t_order_detail- 问题
这样配置绑定表会导致读取的时候,yml 会将 t_order, t_order_detail 作为绑定表集合中的两个绑定表关系, 导致每一个绑定表关系只有一个值, 就是这个表本身, 这样 shardingshpere 就不能知道 t_order,t_order_detail 这两张表属于绑定表
- 问题
- 配置
- 修正后
- 配置
1
2
3
4
5
6
7
8
9spring:
shardingsphere:
# 数据源配置
datasource:
...
rules:
...
binding-tables:
- t_order,t_order_detail
- 配置
- 修正前
Debug
遇到的问题
问题一:自定义算法提示没有实现 spi
1 | Caused by: org. Apache. Shardingsphere. Infra. Util. Spi. Exception. ServiceProviderNotFoundException: SPI-00001: No implementation class load from SPI ` org.apache.shardingsphere.sharding.spi.ShardingAlgorithm ` with type ` COSTOM_DATE `. |
在 shardingsphere 5.2 版本中,shardingsphere 强制使用 spi 的方式对实现类进行注册, 而不像 4.2 的时候通过实现接口, 将实现类配置到配置文件如 yml 或 properties 中就可以了. 所以需要再 resource 下新建对应的 spi 的接口文件如 org. Apache. Shardingsphere. Sharding. Spi. ShardingAlgorithm, 文件内容为自定义的实现类路径 com.wl.algorithm.sharding.CustomDateShardingAlgorithm
问题二 : bindtables 未生效
原因就是之前讲的 yml 配置问题, 格式不对.
Debug 过程总结
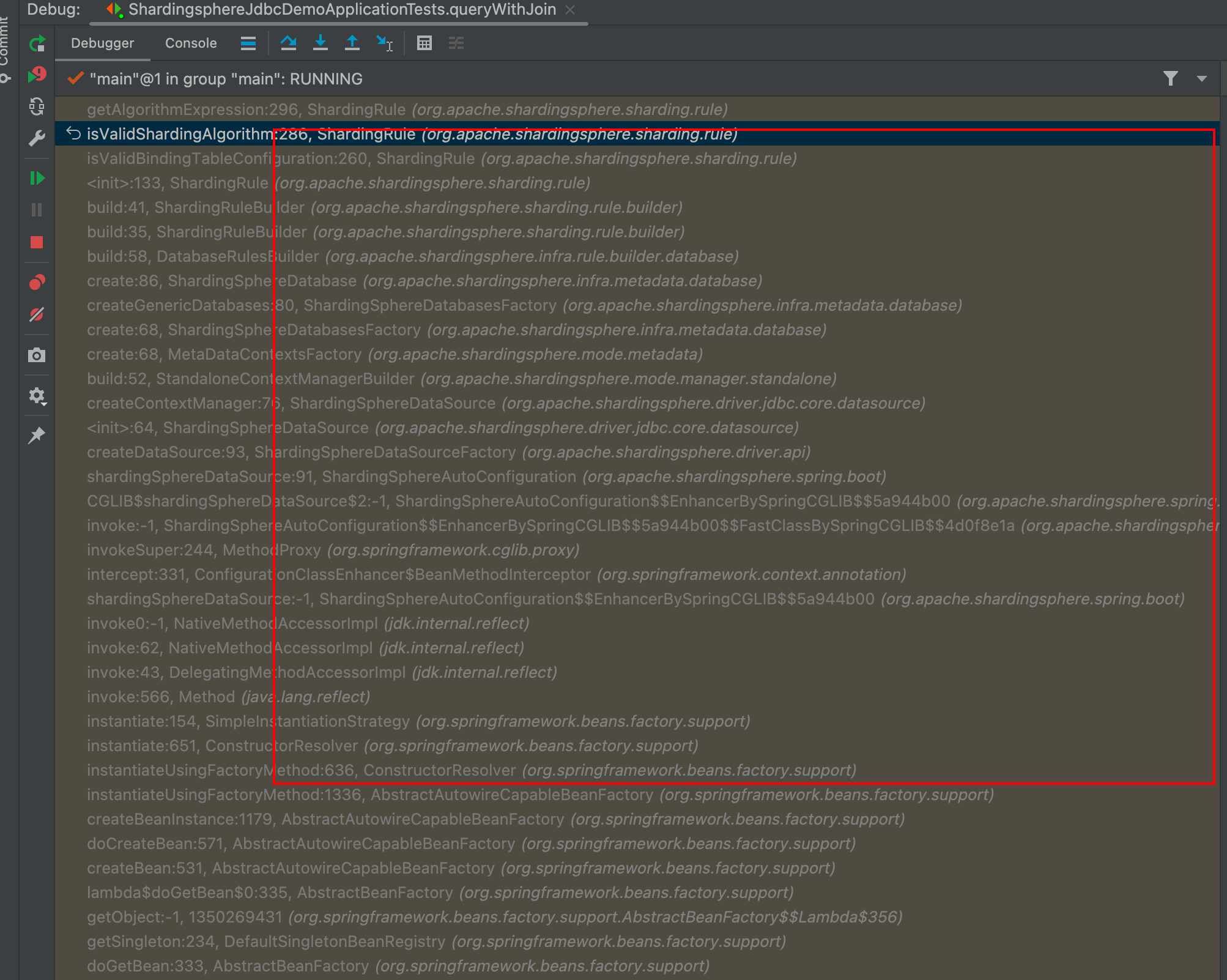
1. 找到程序 debug入口
- 找到 Debug 的入口, 即 shardingsphere 代码执行的哪些过程, 需要再这过程中打断点才能看具体配置读取后 shardingsphere 是如何处理这些配置参数的, 并通过读取配置参数进行正确的分库分表等处理的.
- 通过 shardingsphere (以下简称 ss) 开放的自定义接口实现 StandardShardingAlgorithm, 知道 shardingsphere 要使用我们的自定义实现, 它会调用我们的实现类中的方法, 如 ss 提供的 StandardShardingAlgorithm 中的两个方法:只要通过 IDEA find usages 就可以找到调用的地方, 可能会有几个, 但是根据类调用的地方根据猜测, 以及尝试 debug 看断点是否进入就可以很快找到调用路径. 通过 IDE debug 进入断点后, 根据 IDEA 提供的 debug 工具, Debugger 窗口, 就可以看到到当前断点之前的整个调用链, 通过这个调用链窗口, 可以去到任意一个节点, 不再需要像无头苍蝇一样整个源码找相关处理源码.
1
2
3
4public interface StandardShardingAlgorithm<T extends Comparable<?>> extends ShardingAlgorithm {
String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<T> shardingValue);
Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<T> shardingValue);
}
2. Debug 相关操作
- Debug 常用调试方式
- 单步跳入 step into : debug 进入函数
- 单步跳过 step over : debug 得到函数执行的结果 (如果调用函数的是)
- 单步跳出 step out : debug 执行函数里面的代码后回到调用该函数的地方
- 执行到调用链上的断点处 resume programe: 执行代码, 在调用链上的断点处暂停
- 忽略断点 mute break point: 忽略断点, 直接执行, 拒绝打断
- 重置调用帧 reset frame/ drop frame: 返回上一个调用帧, 刚才没看清, 重新走一下, 不需要在重新从最开始的地方一步步 debug 进来. 调用链很长, 而且代码不熟悉时, 这个最有用的工具
- 其他辅助方式
- 书签: 当调用链太长, 而且有些地方没必要或者断点打太多的时候, 可以使用书签进行记录一些那些地方调试的时候注意看一下. 而且通过书签可以很方便回到标记的位置
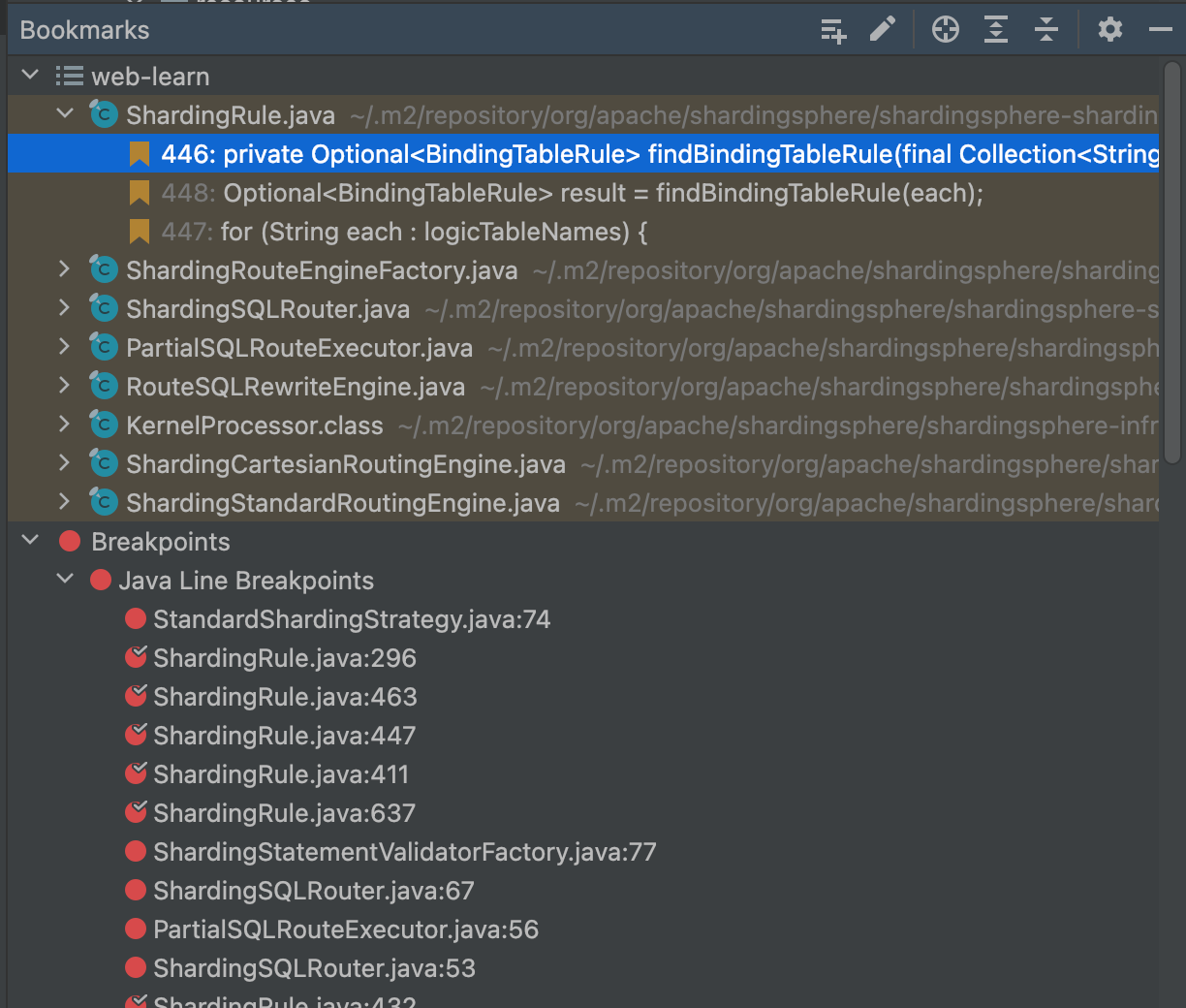
- 利用 IDEA 断点执行条件: 可以在断点上设置执行表达式, 当符合条件的时候暂停, 用得不多
- 使用执行表达式, 随时随地查看调用后的结果, 但是 debug 变量窗口很多时候都已经有结果了
- 书签: 当调用链太长, 而且有些地方没必要或者断点打太多的时候, 可以使用书签进行记录一些那些地方调试的时候注意看一下. 而且通过书签可以很方便回到标记的位置
最后: 一定要注意看日志
有时候很简单的配置问题, 或者编码实现的问题, 其实日志已经很清楚明白讲述了异常的位置, 根据信息去到对应的位置看代码, 大部分情况下都可以发现问题. 根据报错就能知道, 哪里发生了空指针或者其他异常, 然后查看为什么产生了这个空指针, 检查对应的配置参数是否配置或者格式是否正确, 这是最高效, 性价比最高的排查方式, 要知道发生了什么问题.
明白了发生了什么问题, 发生问题的地方一时看不明白为什么发生, 再带着这个明确的问题去 debug, 这样 debug 的时候就不需要管其他东西, 只要专注于问题, 基于问题去 debug, 才能尽可能快速的找到问题原因.
否则就算能够找到入口 debug, 但是如果不明确问题, 而且现在的开源软件那么大, 一路debug下来别说使用者, 连开发者自己都可能不是很清晰, 那么长的调用链, 没有明确关注的地方, 要知道问题在哪太难了. 而且知名开源软件一般 bug 都不多, 大部分情况下软件出了问题一般也不是 bug, 如果不明确问题, 往往排查了很久, 最后其实是自己的配置问题, 就是花几分钟调整一下配置的问题. 浪费了时间, 最后只能安慰自己起码收获了教训.